Wenn Sie in einer Datenfluss-Task mit dem OLE DB Datenziel in
eine SQL Server Datenbanktabelle schreiben, gibt es zwei Möglichkeiten des Datenzugriffsmodus:
"Tabelle oder Sicht" und "Tabelle oder Sicht – schnelles Laden".
Nachfolgend möchte ich die Unterschiede
zwischen diesen beiden Möglichkeiten genauer beleuchten.
Der normale Ladevorgang
Die Konfiguration dieses Datenzugriffsmodus ist sehr
einfach: Es gibt keine weiteren Einstellmöglichkeiten im Standard-Editor. Mit
dem Profiler können Sie herausfinden, wie dieser Modus funktioniert:
- Zunächst erzeugt das SSIS-Paket einmal einen Aufruf
der gespeicherten Prozedur sp_cursoropen.
- Anschließend erzeugt es für jeden zu schreibenden
Datensatz einen Aufruf der gespeicherten Prozedur sp_cursor.
Vorteil: Jede einzelne Datenzeile, die beim Schreiben in die
Zieltabelle einen Fehler verursacht, kann am Fehlerausgang des OLE DB
Datenziels abgegriffen und gesondert weiterverarbeitet werden.
Nachteil: SQL Server protokolliert in diesem Modus jeden Schreibvorgang vollständig im Transaktionsprotokoll. Die vollständige Protokollierung der einzelnen Schreibvorgänge
kann das Einfügen großer Datenmengen erheblich ausbremsen.
Der schnelle Ladevorgang
 |
| Konfigurationsdialog für schnelles Laden |
Diesen Nachteil kann das schnelle Laden aufheben. Wiederum
ist es der Profiler, mit dem Sie herausfinden können, welche SQL Statements
SSIS an die Zieldatenbank schickt. Diesmal sieht der Ablauf anders aus:
- Das SSIS-Paket erzeugt ein einziges INSERT BULK
Statement.
Vorteil: Ein BULK- oder Masseneinfügevorgang wird im SQL
Server minimal protokolliert, was einerseits zu einem erheblich höheren
Datendurchsatz führt, aber andererseits mit Einschränkungen beim
Wiederherstellen der Zieldatenbank verbunden ist (Stichwort: eingeschränktes
Point-In-Time Recovery). In aller Regel überwiegen die Vorteile des höheren
Datendurchsatzes.
Nachteil: Bei dieser Variante wird das Einfügen im Rahmen
einer Transaktion durchgeführt. Wenn also 100.000 Zeilen ins Ziel eingefügt
werden und die letzte Zeile beim Schreiben einen Fehler auslöst, dann rollt der
Zielserver die gesamte Transaktion zurück und der ganze Einfügevorgang war
wirkungslos.
Um diesen Nachteil wettzumachen, können Sie folgendes
Entwurfsmuster anwenden:
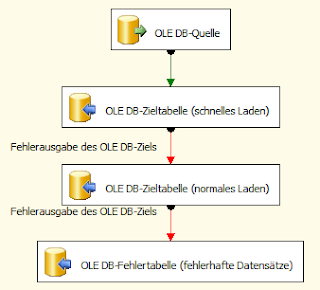 |
| Entwurfsmuster für die Auswertung fehlerhafter Zeilen beim schnellen Laden |
Solange im Rahmen einer Transaktion keine fehlerhaften
Zeilen auftreten, leistet das OLE DB Ziel mit schnellem Laden ganze Arbeit. Falls
eine fehlerhafte Zeile das schnelle Laden abbricht, reicht das erste OLE DB
Ziel alle Datensätze dieser Transaktion an das nächste OLE DB Ziel weiter, das
die Datensätze normal lädt. Das geht langsamer, hat aber den Vorteil, dass die
fehlerhafte Zeile als einzige in der Fehlertabelle (drittes OLE DB Ziel) landet;
alle anderen Datensätze erreichen das gewünschte Ziel.
Feinheiten beim schnellen Ladevorgang
Beim schnellen Laden gibt es (abgesehen von den vier Haken
für Beibehalten der Identitätswerte, Behandeln von NULL-Werten, Setzen einer Tabellensperre
und das Überprüfen von Einschränkungen) zwei Einstellungen, die für das Verarbeiten
von Transaktionen von Bedeutung sind:
- Maximale Einfügungcommitgröße (maximum insert
commit size) bestimmt die Anzahl von Zeilen, nach denen die Transaktion spätestens
beendet wird. Mit der Standardeinstellung (siehe Bild) wird wohl jeder
realistische Ladevorgang im Rahmen einer Transaktion durchgeführt. Aber ist das
auch gut? Bei sehr großen Datenmengen kann das Transaktionsprotokoll der
Zieldatenbank dadurch auf eine erhebliche Größe anwachsen. Außerdem sperrt der
Datenbankserver immer mehr Datensä tze (Stichwort: Sperrenausweitung / lock
escalation), was andere Prozesse behindert könnte. Um dem entgegenzuwirken, sollten
Sie die Größe einer Transaktion zum Beispiel auf 5000 Zeilen begrenzen. Dann beendet
der Datenflusstask immer nach 5000 Zeilen die Transaktion und beginnt eine neue.
- Zeilen pro Batch ist eine Größe, zu der
praktisch keine Dokumentation zu finden ist. Das hängt damit zusammen, dass der
INSERT BULK Befehl (Verwechslungsgefahr: es handelt sich dabei nicht um das
BULK INSERT Kommando), den SSIS generiert, nur sehr oberflächlich dokumentiert
ist. Programmierer können ihn mit der .NET Klasse SQLBulkCopy verwenden, aber auch hier findet sich
keine weitergehende Dokumentation zur Batchgröße. So bleibt uns
SSIS-Entwicklern nichts übrig, als im Zweifelsfall verschiedene Werte für
diesen Parameter auszuprobieren und den für unseren Fall besten Wert
experimentell zu ermitteln.
Vielen Dank an Torsten Strauß für seine Hinweise zu diesem
Thema! Über Kommentare und Ergänzungen zu diesem Thema freue ich mich – vielleicht lässt sich
ja doch noch mehr Licht in diese Ecke des OLE DB Ziels bringen.






